


A geração de imagens por inteligência artificial (IA) sempre enfrentou dificuldades em criar resultados consistentes, frequentemente cometendo erros bizarros em detalhes como dedos e simetria facial. Além disso, esses modelos podem falhar completamente quando solicitados a gerar imagens em diferentes tamanhos e resoluções. No entanto, uma nova solução desenvolvida por cientistas da computação da Rice University pretende corrigir essas falhas.
Moayed Haji Ali, doutorando em ciência da computação na Rice University, desenvolveu um método chamado ElasticDiffusion. Este método utiliza modelos de difusão pré-treinados para gerar imagens, uma classe de IA generativa que “aprende” adicionando camadas de ruído aleatório às imagens em que foi treinada e, posteriormente, gera novas imagens removendo esse ruído.
A pesquisa foi apresentada na IEEE 2024 Conference on Computer Vision and Pattern Recognition (CVPR) em Seattle.
O problema com modelos de difusão atuais
Modelos de difusão populares como Stable Diffusion, Midjourney e DALL-E são conhecidos por gerar imagens realistas. No entanto, eles possuem uma limitação relevante: só conseguem criar imagens quadradas. Quando se trata de diferentes proporções, como as de um monitor widescreen (16:9) ou de um smartwatch, esses modelos falham ao gerar elementos repetitivos e distorcidos.
Esta limitação ocorre devido ao treinamento dos modelos em imagens de uma única resolução. Com isso, a tentativa de gerar imagens em proporções diferentes resulta em anomalias visuais, como pessoas com seis dedos ou carros estranhamente alongados.

Exemplo de IA com falha na simulação de dedos de mão humana
Esse problema é agravado pelo fenômeno conhecido como overfitting, no qual o modelo se torna excessivamente bom em criar dados semelhantes ao que foi treinado, mas incapaz de se adaptar a outras variações. Ou seja, o modelo que apresenta overfitting é incapaz de fazer generalizações para o usar o que aprendeu em outro conjunto de dados.
O método ElasticDiffusion
O método ElasticDiffusion propõe uma solução para esse problema separando o “sinal” das imagens geradas em dois tipos de dados: local e global. O sinal local contém detalhes em nível de pixel, enquanto o sinal global fornece um contorno geral da imagem. Em modelos de difusão convencionais, esses sinais são processados juntos, o que leva a problemas quando a IA tenta acomodar proporções diferentes.
Então, o tratamento de Haji Ali separa os sinais em caminhos de geração condicionais e incondicionais. Isso permite que o modelo aplique detalhes locais em quadrantes da imagem, preenchendo um quadrado de cada vez. O sinal global, que define a proporção da imagem e o conteúdo geral, é mantido separado, evitando a repetição e confusão de dados.
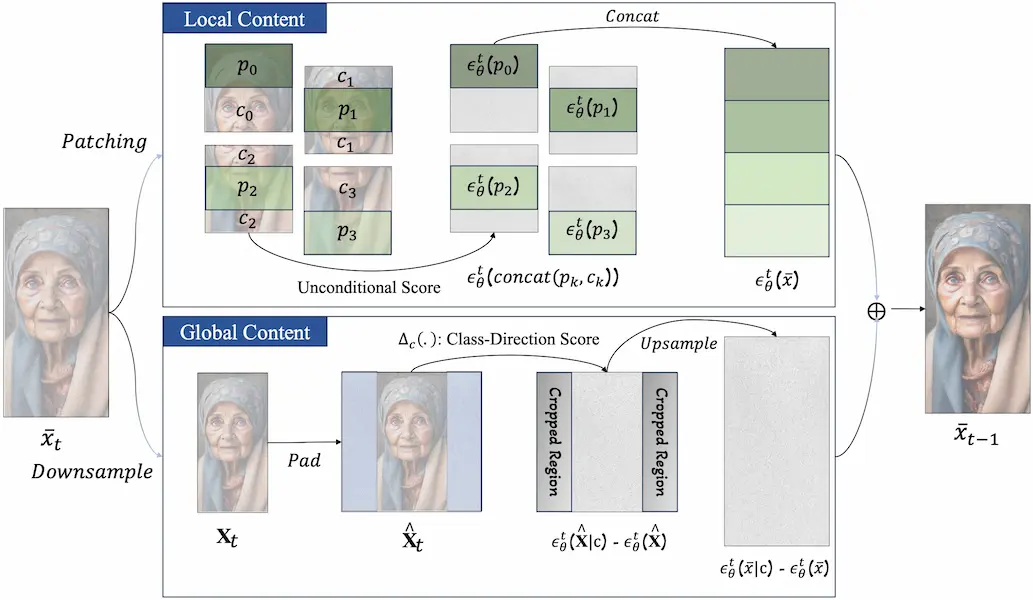
Esquemático do tratamento de sinais feito pelo modelo ElasticDiffusion (HAJI ALI, Moayed; BALAKRISHNAN, Guha; ORDÓÑEZ-ROMÁN, Vicente. ElasticDiffusion: Training-free Arbitrary Size Image Generation through Global-Local Content Separation. 2023)
Como resultado, o ElasticDiffusion consegue criar imagens mais limpas, independentemente da proporção, sem necessidade de treinamento adicional.

Comparação de imagens geradas pelo modelo Elastic Diffusion e StableDiffusion (HAJI ALI, Moayed; BALAKRISHNAN, Guha; ORDÓÑEZ-ROMÁN, Vicente. ElasticDiffusion: Training-free Arbitrary Size Image Generation through Global-Local Content Separation. 2023)
Desafios do modelo e futuro da pesquisa
Embora o ElasticDiffusion apresente uma solução que parece promissora, ele possui uma desvantagem em relação aos modelos de difusão existentes: o tempo. Atualmente, a técnica de Haji Ali leva de 6 a 9 vezes mais tempo para gerar uma imagem. Assim, o objetivo futuro é reduzir esse tempo para se equiparar a modelos como o Stable Diffusion ou o DALL-E.
Haji Ali espera que sua pesquisa conduza a um melhor entendimento de por que os modelos de difusão apresentam repetição e não se adaptam a diferentes proporções, criando assim uma estrutura que possa se adaptar a qualquer proporção, mantendo o mesmo tempo de inferência.
Referência:
HAJI ALI, Moayed; BALAKRISHNAN, Guha; ORDÓÑEZ-ROMÁN, Vicente. ElasticDiffusion: Training-free Arbitrary Size Image Generation through Global-Local Content Separation. 2023. Disponível em: https://arxiv.org/abs/2311.18822.
-

Escrito por:
Caio Póvoa











0 comentários